GPT
[파이썬] 특성 추출 - TF-IDF ( 자연어 처리 / 벡터화 )
파이썬 서퍼
2021. 1. 20. 12:35
728x90

◎ TF - IDF ( Term Frequency - Inverse Document Frequency ) :
단어의 빈도(Term Frequency)와 역 문서 빈도(Inverse Document Frequency)를 토대로,
특정 문서 내에 어떤 단어가 얼마나 중요한 지를 나타내는 통계적 수치.
>> 다른 문서에는 잘 등장하지 않지만, 이 문서에는 유독 많이 쓰인 단어가 이 문서의 키워드
▷ TF (Term Frequency) 는 단어 빈도를 나타내며 문서 내에서 특정 단어가 몇 번 발견되었는지를 계산.
문서-단어 행렬이 곧 단어들의 TF 값을 구한 것임.
▷ IDF (Inverse Document Frequency) 는 DF 의 역수이며, 특정 단어가 발견되는 문서의 수를 뜻한다.
다시 말해, 특정 문서가 아닌 대부분의 문서에서 발견되는 단어는 그만큼 흔하게 사용되어 중요한 의미를 갖지 않는다고 볼 수 있다.

from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import numpy as np
corpus = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
vect = CountVectorizer()
document_term_matrix = vect.fit_transform(corpus) # 문서-단어 행렬
tf = pd.DataFrame(document_term_matrix.toarray(), columns=vect.get_feature_names())
# TF (Term Frequency)
D = len(tf)
df = tf.astype(bool).sum(axis=0)
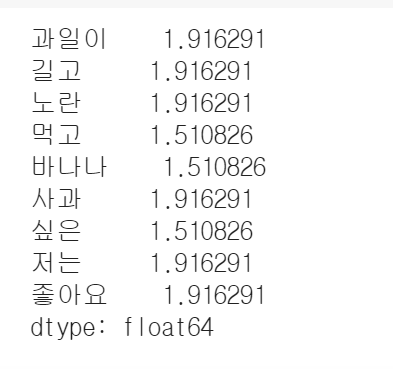
idf = np.log((D+1) / (df+1)) + 1 # IDF (Inverse Document Frequency)
# TF-IDF (Term Frequency-Inverse Document Frequency)
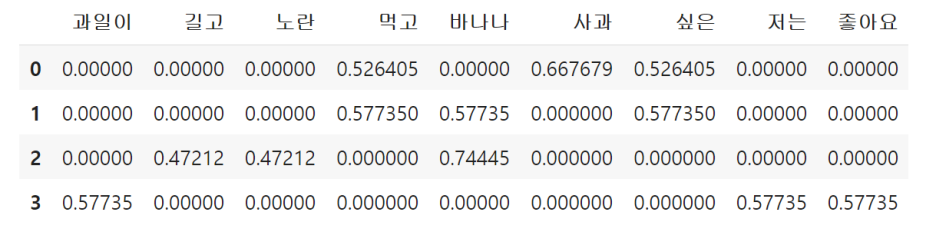
tfidf = tf * idf
tfidf = tfidf / np.linalg.norm(tfidf, axis=1, keepdims=True)

반응형